Metacat: メタデータとデータの管理サーバ
Metacat: メタデータとデータの管理サーバ
Metacat のハーベスタは、それぞれ独自のデータ管理システム (たとえば SRB や PostgreSQL のような)から EML 文書を取り出して自分のリポジトリに追加(または更新) することを自動的に実行してくれるオプション機能である。 いつデータを集めるか、どのデータを集めるかはローカルサイトが制御する。
たとえば、Long Term Ecological Research Network (LTER) は Metacat ハーベスタを使って、26 の異なるサイトに格納されているデータを 集めて集中型リポジトリを作成している。それらのサイトはどれも EML メタデータを格納しているが、しかし異なるデータ管理システムを 使用している。 データが集められて集中型リポジトリに入れられると、そのデータは KNBネットワーク上に複製され、その情報はよりいくらか大きな科学コミュニティ に対して明らかにされる。
ハーベスタが正しく設定されると、リストにある文書は 定期的なスケジュールに従って取り出されてアップロードされる。 この機能を使用する前に、自分の Metacat と相手サイト(別名 「ハーベストサイト」)の両方を設定しなければならない。 またローカルサイトは Metacat サーバに集められるべき文書の リストを与えなければならない。
ハーベスタを使って文書を取り出す前に、 metacat.properties ファイル内の設定項目を用いてこの機能を設定しなければ ならない。 なお、ハーベスタを接続してデータを取り出す先の各サイトも設定 しなければならない(10.3節を参照)。
#Before you can use the Harvester to retrieve documents, you must configure the #feature using the settings in the metacat.properties file. Note that you must #also configure each site that the Harvester will connect to and retrieve #documents from (see section 7.2 for details).
ハーベスタの設定情報は metacat.properties ファイルで管理されている。 このファイルの場所は:
<CONTEXT_DIR>/WEB_INF/metacat.properties
ハーベスタのプロパティはグループ化されており、以下のコメント行から 始まる。:
# Harvester properties
ハーベスタを設定するには、 metacat.properties を編集して harvesterAdministrator および smtpServer プロパティに 適切な値を設定する。 また他のハーベスタ用パラメータを調整したいと思うかもしれないが、 それぞれ以下の表で説明している。
| プロパティ | 説明と値 | |
|---|---|---|
| connectToMetacat | ハーベスタが Metacat に接続して、取り出した文書をアップロードするべきかどうかを決める。 大抵の状況では true に設定する(初期状態ではそうなっている)。ハーベスタのテストのため、 サイトから文書を取り出すものの、Metacat に接続して文書をアップロードするのは避ける場合は、 false に設定する。 Values: true/false |
|
| delay | 最初の収集を始める前にハーベスタが待機する時間(単位は時間)。 たとえば、ハーベスタが午後1時に実行を開始し、delay が 12 に設定されている場合、 ハーベスタは最初の収集を午前1時に開始する。 Default: 0 |
|
| harvesterAdministrator | ハーベスタ管理者のメールアドレス。ハーベスタは収集のたびにこのアドレスに報告メールを送る。 カンマまたはセミコロンで区切ると複数のアドレスを入力できる。 (たとえば name1@abc.edu,name2@abc.edu ) Values: メールアドレス、またはカンマ・セミコロン区切りの複数のメールアドレス |
|
| logPeriod | ハーベスタのログ内容を保持する日数。ハーベスタのログ内容には、どの文書が収集されたか、 どのサイトからか、その時に何かエラーが発生したか、という情報が記録される。 logPeriod の日数よりも古いログ内容は、各収集作業の終わりにデータベースから排除される。 Default: 90 |
|
| maxHarvests | ハーベスタが停止する前に実行するべき収集作業の最大回数。 maxHarvests の値が 0 または負の数であれば、ハーベスタは無限に実行する。 Default: 0 |
|
| period | 収集の時間間隔の時間数。ハーベスタは指定の時間間隔ごとに新しい収集作業を実行する。 (無限に、または収集の最大実行回数になるまで。これは maxHarvests の値に依存する) Default: 24 |
|
| smtpServer | ハーベスタがハーベスタ管理者とサイト責任者に対してメールを送るのに使用する SMTP サーバ。 (たとえば somehost.institution.edu ) なお、初期設定値はハーベスタのホスト機が SMTP サーバとして設定されている場合にのみ機能する。 Default: localhost |
|
| Harvester Operation Properties (GetDocError, GetDocSuccess, etc.) | Harvester Operation properties は、ハーベスタが実行された作業について報告する時に ログ内容やメールに入れるものを指定する。 たいていの状況では、これらのプロパティは修正するべきではない。 |
Configuring a Harvest Site (Instructions for Site Contact) ハーベストサイトの設定(サイト責任者のための説明) ———————————————————-
Metacat のハーベスタが設定されると、外部サイトは登録および取り出すべき ファイルについての情報を送ることができる。 各外部サイトはサイト責任者を持たなければならない。それはそのサイトの登録と 収集される EML ファイルのリスト(「ハーベストリスト」)の作成に責任を持つ 人物であり、収集作業の報告を確認する人物である。 サイト責任者はいつでもハーベスタからそのサイトを登録抹消することができる。
ハーベスタを使用するには、
外部サイトをハーベスタに登録するには、サイト責任者が Metacat の Harvester Registration ページにログインし、そのサイトおよび 収集方法についての情報を入力するべきである。
ウェブブラウザを使って、Metacat の Harvester Registration ページにログインする。 Harvester Registration ページはスキンディレクトリの内側にある。たとえば、 登録しようとしている Metacat サーバが以下のURLにある場合、
http://somehost.somelocation.edu:8080/knb/index.jsp
Harvester Registration ページには以下でアクセスできる。
http://somehost.somelocation.edu:8080/knb/style/skins/knb/harvesterRegistrationLogin.jsp
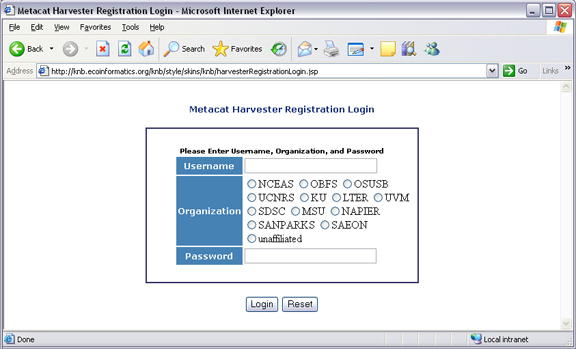
Metacat の Harvester Registration ページ
Metacat アカウント情報を入力し、送信を押して、 Harvester Registration ページから Metacat にログインする。
註: ある状況では、登録されたデータが単独のユーザによって登録されたように 見えないように、個人のアカウントよりも匿名の「サイト」アカウントで ログインする必要があるかも知れない。 たとえば、ある情報管理者 (jones) が Georgia Coastal Ecosystems サイトから 科学者チーム (jones, smith, barney) によって作成されたデータを登録した ものの、その登録データが “jones” というよりもサイト全体からのものであるという ことを示すために、(サイトの略称である “GCE” という名前の) 専用 アカウントでログインしてもよい。
サイトの情報、および、どのくらいの頻度で収集作業を行って欲しいかという情報を入力し、 Register ボタンをクリックする(図 7.2)。 Harvest List URL はハーベストリストの場所を示すべきである。それは 収集されるべき文書のリストを格納した XML ファイルである。 もしまだハーベストリストを持っていないなら、次節に作成についての 情報があるので見るように。
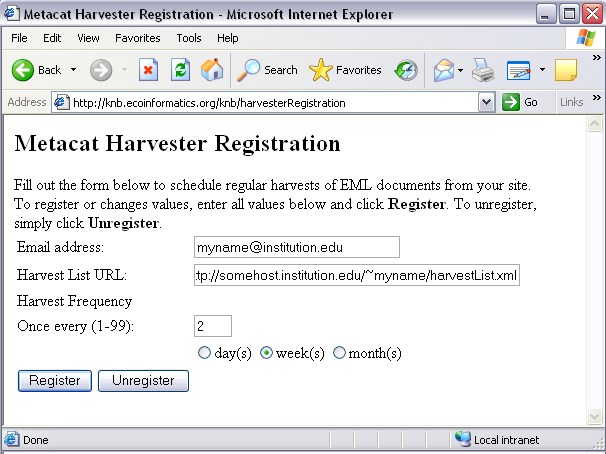
サイト情報および希望する収集頻度を入力する。
上図の設定例では、2週間ごとにそのサイトから文書を収集するように ハーベスタに指示している。 ハーベスタは “http://somehost.institution.edu/~myname/harvestList.xml” にあるそのサイトのハーベストリストにアクセスし、また報告メールを サイト責任者(メールアドレス “myname@institution.edu“)に送信する。 なお、カンマまたはセミコロンで区切ることで複数のメールアドレスを 入力することができる。 たとえば、 “myname@institution.edu,anothername@institution.edu”
ハーベストリストは、収集されるべき文書のリストを格納した XML ファイルである。 そのリストはサイト責任者によって作成され、そのサイト上の、 ハーベスタ登録手順の最中に指定した場所に保管される(詳しくは 前節を参照)。 そのリストは手作業で作ることもできるが、Metacat の ハーベストリストエディタを用いて自動的に生成し、必要な XML シェーマに 適合するようにリストを構造化することもできる (この節の終わりに図を示した)。 この節では、ハーベストリストの作成中にどのような情報が必要なのかを 示し、ハーベストリストエディタの設定と使用法を示す。 なお、ハーベストリストエディタを使用するには Metacat のソース配布物を 持っていなければならない。
ハーベストリストには、Metacat が指定の各EMLファイルを同定し取り出すことが できるように情報が格納されている。 そのリストにおいて個々の文書は、 docid, documentType, documentURL とともに記述されなければならない。 (表を参照)
表: 個々の EML ファイルについて、ハーベストリストに含まれなければならない情報
| 項目 | 説明 |
|---|---|
| docid | docid は個々のEML文書をユニークに識別する。個々の docid は 3つの要素からできている。 scope この文書が属している文書グループ identifier そのスコープの中でその文書をユニークに識別する番号 revision 最新のリビジョンを示す番号 たとえば、有効な docid は次のようになっている: demoDocument.1.5, ここで demoDocument は scope であり、1 は identifier で、 5 は revision 番号である。 |
| documentType | documentType は文書の EML としての種類を識別する。 たとえば、 “eml://ecoinformatics.org/eml-2.0.0”. |
| documentURL | documentURL には、ハーベスタが HTTP 経由でその文書を見つけ出して取り出すことができる場所を 指定する。ハーベスタにはその URL の内容に対する読み出し権限が与えられなければならない。 例 “http://www.lternet.edu/~dcosta/document1.xml”. |
下のハーベストリストの例では 2つの <document> 要素が含まれており、 ハーベスタが EML 文書を取り出して Metacat にアップロードするのに 必要な情報が指定されている。
<!-- Example Harvest List -->
<?xml version="1.0" encoding="UTF-8" ?>
<hrv:harvestList xmlns:hrv="eml://ecoinformatics.org/harvestList" >
<document>
<docid>
<scope>demoDocument</scope>
<identifier>1</identifier>
<revision>5</revision>
</docid>
<documentType>eml://ecoinformatics.org/eml-2.0.0</documentType>
<documentURL>http://www.lternet.edu/~dcosta/document1.xml</documentURL>
</document>
<document>
<docid>
<scope>demoDocument</scope>
<identifier>2</identifier>
<revision>1</revision>
</docid>
<documentType>eml://ecoinformatics.org/eml-2.0.0</documentType>
<documentURL>http://www.lternet.edu/~dcosta/document2.xml</documentURL>
</document>
</hrv:harvestList>
このリストを手作業で整形するよりも、Metacat のハーベストリストエディタを 使ってリストを整えて編集する方がいいと思うだろう。 ハーベストリストエディタはハーベストリストを行と項目の表として表示する。 テーブルの個々の行はハーベストリストファイルにおける単一の <document> 要素に対応する。(すなわち、ひとつの EML 文書である) 行番号は単に見やすさのためであり、編集はできない。
新しい文書をハーベストリストに追加するには、 編集可能な 5項目すべてに値を入力する(”Row #” 項目以外のすべての項目)。 一部だけに入力すると無効なハーベストリストになってしまい、エラーが 生じるだろう。
エディタの一番下にあるボタンは、ある場所から他の場所に行を 切り取ったりコピーしたり貼付けたりするのに使える。 行を選んで望みのボタンをクリックするか、または Paste Defaults ボタンをクリックして現在選択中の行に デフォルト値を貼付ける(デフォルト値はエディタの設定ファイルで 指定する。後述)。 註: 常にひとつの行だけを選択できる。切り取り、コピー、貼付け操作は 単一の行にのみ働き、行の範囲には効かない。
ハーベストリストエディタを動かすには、Metacat のソースコードが インストールされている端末から、
システムコマンドのウィンドウか、ターミナルウィンドウを開く。
METACAT_HOME 環境変数を Metacat のインストールディレクトリに 設定する。以下に例を示す。
Windows では:
set METACAT_HOME=C:\somePath\knb
Linux/Unix (bash shell) では:
export METACAT_HOME=/home/somePath/metacat
以下のディレクトリに移動する。
Windows では:
cd %METACAT_HOME%\lib\harvester
Linux/Unix では:
cd $METACAT_HOME/lib/harvester
OSごとに適切なハーベスタ用シェルスクリプトを実行する。
Windows では:
runHarvestListEditor.bat
Linux/Unix では:
sh runHarvestListEditor.sh
するとハーベストリストエディタが開く。
ハーベストリストを調整したい場合は(たとえば、エディタが開いた時に 自動的に開くデフォルトのリストを指定したり、デフォルト値を指定する)、 .harvestListEditor という名前のファイルを作成する (先頭がドット文字であることに注意)。 テキストエディタでそのファイルを作成し、サイト責任者のホーム ディレクトリに置く。ホームディレクトリを調べるには、 システムコマンドウィンドウかターミナルウィンドウを開いて 以下を入力する。
Windows では:
echo %USERPROFILE%
Linux/Unix では:
echo $HOME
この設定ファイルには、このエディタをもっと便利に使えるようにするための 多くのプロパティが含まれている。 設定ファイルの例を以下に示す。 また個々の設定プロパティについてより詳しい情報が表に記されている。
.harvestListEditor 設定ファイルの例
defaultHarvestList=C:/temp/harvestList.xml
defaultScope=demo_document
defaultIdentifier=1
defaultRevision=1
defaultDocumentURL=http://www.lternet.edu/~dcosta/
defaultDocumentType=eml://ecoinformatics.org/eml-2.0.0
ハーベストリストエディタの設定プロバティ
| プロパティ | 説明 |
|---|---|
| defaultHarvestList | エディタ起動時に自動的に開くハーベストリストファイルの場所。 一番頻繁に編集すると予想されるハーベストリストファイルのパスを設定する。 例: /home/jdoe/public_html/harvestList.xml C:/temp/harvestList.xml |
| defaultScope | Paste Defaults ボタンをクリックした時にエディタの Scope 欄に貼付けられる値。 Scope 欄には、その EML 文書がどの文書群に属するのかを示すための象徴的な識別子を 入力するべきである。 例: xyz_dataset 初期値: dataset |
| defaultIdentifer | Paste Defaults ボタンをクリックした時にエディタの Identifier 欄に貼付けられる値。 Identifier 欄には、そのスコープ内でこの EML 文書を識別するための数値を 入力するべきである。 |
| defaultRevision | Paste Defaults ボタンをクリックした時にエディタの Revision 欄に貼付けられる値。 Revision 欄には、その Scope と Identifier の中で、この EML 文書のリビジョン番号を 示す数値を入力するべきである。 例: 2 初期値: 1 |
| defaultDocumentType | Paste Defaults ボタンをクリックした時にエディタの DocumentType 欄に貼付けられる 文書型を指定する。 初期値: eml://ecoinformatics.org/eml-2.0.0 |
| defaultDocumentURL | Paste Defaults ボタンをクリックした時にエディタの URL 欄に貼付けられる URL (または URL の一部)。典型的には、収集される EML 文書に共通の URL の一部を設定する。 例: http://somehost.institution.edu/somepath/ 初期値: http:// |
ハーベストリスト用の XML シェーマ
<?xml version="1.0" encoding="UTF-8"?>
<!-- edited with XMLSPY v5 rel. 4 U (http://www.xmlspy.com) by Matt Jones (NCEAS) -->
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:hrv="eml://ecoinformatics.org/harvestList" xmlns="eml://ecoinformatics.org/harvestList" targetNamespace="eml://ecoinformatics.org/harvestList" elementFormDefault="unqualified" attributeFormDefault="unqualified">
<xs:annotation>
<xs:documentation>This module defines the required information for the harvester to collect documents from the local site. The local system containing this document must give the Metacat Harvester read access to this document.</xs:documentation>
</xs:annotation>
<xs:annotation>
<xs:appinfo>
<tooltip/>
<summary/>
<description/>
</xs:appinfo>
</xs:annotation>
<xs:element name="harvestList">
<xs:annotation>
<xs:documentation>This represents the local document information that is used to inform the Harvester of the docid, document type, and location of the document to be harvested.</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element name="document" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="docid">
<xs:annotation>
<xs:documentation>The complete document identifier to be used by metacat. The docid is a compound element that gives a scope for the identifier, an integer local identifer that is unique within that scope, and a revision. Each revision is assumed to specify a unique, non-changing document, so once a particular revision is harvested, there is no need for it to be harvested again. To trigger a harvest of a document that has been updated, increment the revision number for that identifier.</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element name="scope" type="xs:string">
<xs:annotation>
<xs:documentation>The system prefix of a metacat docid that defines the scope within which the identifier is unique.</xs:documentation>
</xs:annotation>
</xs:element>
<xs:element name="identifier" type="xs:long">
<xs:annotation>
<xs:documentation>The local (site specific) portion of the identifier (docid) that is unique within the context of the scope.</xs:documentation>
</xs:annotation>
</xs:element>
<xs:element name="revision" type="xs:long">
<xs:annotation>
<xs:documentation>The revision identifier for this document, indicating a unique document version.</xs:documentation>
</xs:annotation>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="documentType" type="xs:string">
<xs:annotation>
<xs:documentation>The type of document to be harvested, indicated by a namespace string, formal public identifier, mime type, or other type indicator. </xs:documentation>
</xs:annotation>
</xs:element>
<xs:element name="documentURL" type="xs:anyURI">
<xs:annotation>
<xs:documentation>The documentURL field contains the URL of the document to be harvested. The Metacat Harvester must be given read access to the contents at this URL.</xs:documentation>
</xs:annotation>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
収集される EML 文書をひと揃い準備するには、それぞれの文書に対して 以下の項目が満たされていることを確認する。
ハーベスタは予定の収集作業が終わるたびに、サイト責任者に報告メールを 送信する。その報告メールには実行内容について(たとえば、どの EML 文書を 収集したのか、エラーは発生したのか)の情報が入っている。 エラーが生ずるとステータス値に 1 が表示される。ステータス値 0 は 作業が首尾よく完了したことを示す。
エラーが報告された時、サイト責任者は、そのエラーの原因がそのサイトで 修正できるものかどうかを明らかにしようとするべきである。 エラーの原因としてよくあるものは、
サイト責任者がエラーの原因とその解決法を明らかにできない場合は、 ハーベスタ管理者に連絡して相談するべきである。
収集を停止するには、サイト責任者がハーベスタの登録を取り消さなければならない。 登録抹消するには、
ウェブブラウザを用いて、Metacat の Harvester Registration ページに ログインする。Harvester Registration ページはスキンディレクトリの 中にある。たとえば、Metacat サーバが以下の URL にある場合は、
http://somehost.somelocation.edu:8080/knb/index.jsp
Harvester Registration ページは以下でアクセスできる。
http://somehost.somelocation.edu:8080/knb/style/skins/knb/harvesterRegistrationLogin.html
Metacat のアカウント情報を入力して送信する。次の画面で、 Unregister をクリックして自分のサイトを削除して収集を停止する。
ハーベスタは、サーブレットとして実行するか、またはコマンドウィンドウ内で 実行できる。大抵の状況では、バックグラウンド処理のサーブレットとして 連続的に動かすのが最良である。しかし、ハーベスタを不定期に使用する つもりか、ハーベスタの機能をテストしたいだけの場合は、 コマンドウィンドウから実行する方がいいかも知れない。
ハーベスタをサーブレットとして実行するには(ソースコードの インストール内容を使用する)、
ソースコード内の HarvesterServlet 項目を囲んでいるコメント記号を 削除する。HarvesterServlet 項目は lib/web.xml.tomcatN の中にある。 ここで tomcatN というのは使用している Tomcat のバージョンに対応する。 たとえば、Tomcat 6 を使用している場合は、lib/web.xml.tomcat6 を 編集する。
<!--
<servlet>
<servlet-name>HarvesterServlet</servlet-name>
<servlet-class>edu.ucsb.nceas.metacat.harvesterClient.HarvesterServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>1</param-value>
</init-param>
<init-param>
<param-name>listings</param-name>
<param-value>true</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
-->
編集したファイルを保存する。
Tomcat を停止する。
Metacat のインストール先の一番上のディレクトリで、以下の Ant コマンドを実行して Metacat を再配置する。
ant cleanweb
ant install
Tomcat を再起動する。なお、ハーベスタの設定のために metacat.properties ファイルを編集しなければならないことに注意。
Tomcat を再起動してから 30秒ほどすると、ハーベスタのサーブレットの 実行が始まる。最初の収集は metacat.properties ファイルに指定した 時間の後に起こる。 サーブレットは、最大収集回数分の収集が完了するか、Tomcat が停止する まで収集作業を継続する。 (収集頻度および最大収集回数もハーベスタのプロパティで設定する)
ハーベスタをコマンドウィンドウで実行するには、
システムコマンドウィンドウまたはターミナルウィンドウを開く。
METACAT_HOME 環境変数に Metacat のインストール先の ディレクトリを設定する。
Windows では:
set METACAT_HOME=C:\somePath\metacat
Linux/Unix (bash shell) では:
export METACAT_HOME=/home/somePath/metacat
以下のディレクトリに移動する。
Windows では:
cd %METACAT_HOME%\lib\harvester
Linux/Unix (bash shell) では:
cd $METACAT_HOME/lib/harvester
その OS にふさわしいハーベスタのシェルスクリプトを実行する。
Windows では:
runHarvester.bat
Linux/Unix (bash shell) では:
sh runHarvester.sh
するとハーベスタアプリケーションの実行が始まる。 最初の収集は metacat.properties ファイルに指定した 時間の後に起こる。 サーブレットは、最大収集回数分の収集が完了するか、Tomcat が停止する まで収集作業を継続する。 (収集頻度および最大収集回数もハーベスタのプロパティで設定する)
ハーベスタは予定の収集作業が終わるたびに、ハーベスタ管理者に報告メールを 送信する。その報告メールには実行内容について(たとえば、どのサイトが 収集されたのか、どの EML 文書を 収集したのか、エラーは発生したのか)の情報が入っている。 エラーが生ずるとステータス値に 1 が表示される。ステータス値 0 は 作業が首尾よく完了したことを示す。
ハーベスタの管理者は、どんなエラーやメッセージに対しても注意を払いながら 報告メールを読むべきである。 ある特定のサイトについてエラーの報告があった場合は、 ハーベスタ管理者はサイト責任者に連絡してエラーの原因と解決法を 明らかにするべきである。 エラーの原因としてよくあるものは、
特定のサイトから独立しているエラーは、ハーベスタ自身か、Metacat か、 データベースとの接続に問題があることを示している。エラーメッセージを 参照してエラーの原因と解決法を明らかにすること。